





使用机器学习和深度学习模型预测汽车价格
 发布日期:2023-06-05
发布日期:2023-06-05
 浏览量:8443
浏览量:8443
 260
+1
260
+1

目标
在本文中,我们将对二手车定价做出预测。我们将使用不同的架构开发多种机器学习和深度学习模型。最后,我们将比较机器学习模型与深度学习模型的性能。
使用的数据
在这种情况下,我们使用了 kaggle 数据集。
有 17 个不同的变量:
IDPrice: 汽车价格(目标栏)LevyManufacturerModelProd. yearCategoryLeather interiorFuel typeEngine volumeMileageCylindersGear box typeDrive wheelsDoorsWheelColorAirbags
要获取数据并将其用于你的调查,请单击以下链接 -
https://www.kaggle.com/datasets/deepcontractor/car-price-prediction-challenge
数据检查
我们将在这部分查看数据。首先,让我们看看数据中的列及其数据类型,以及任何缺失值。
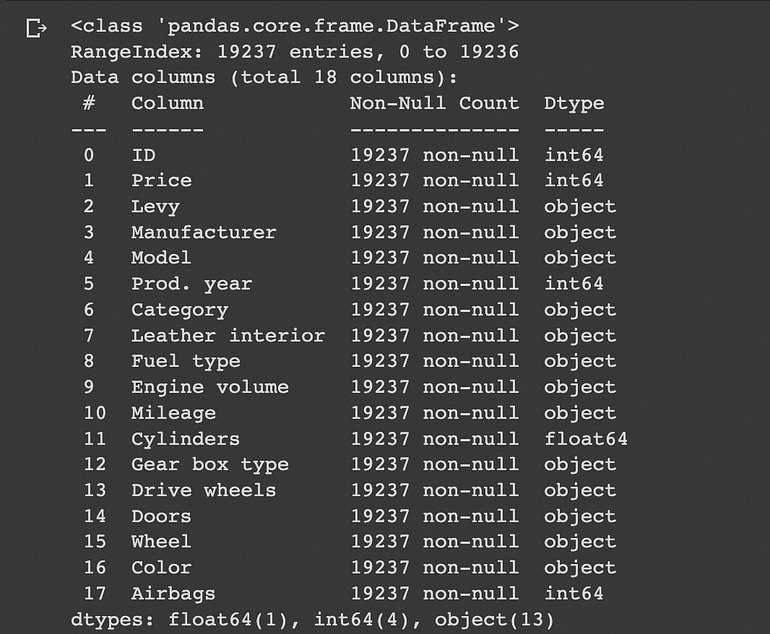
数据集的信息
我们可以看到数据集有 19237 行 18 列。
有五个数字列和十三个类别列。我们可以立即观察到数据中没有缺失数字。
“Price”列/特征将是项目的目标列或相关特征。
让我们看看数据分布。
数据准备
在这里,我们将清理数据并为模型训练做准备。
“ID”列
我们删除“ID”列,因为它与汽车价格预测无关。
Levy 列
检查'Levy'列后,我们发现它确实包含缺失值,但它们在数据中表示为'-',这就是为什么我们无法在数据中更早地捕获缺失值.
在这种情况下,如果没有“Levy”,我们会将“Levy”列中的“-”替换为“0”。我们也可以用“均值”或“中值”来推断它,但你必须做出该决定。
Mileage 列
这里的“Mileage”列表示汽车行驶了多少公里。每次阅读后,“公里”都写在列中。我们将删除它。
**“Engine Volume”列 **
与“Engine Volume”列一起,还写入了发动机的“种类”(涡轮增压或非涡轮增压)。我们将添加一个新列来显示“引擎”的“类型”。
处理“离群值”
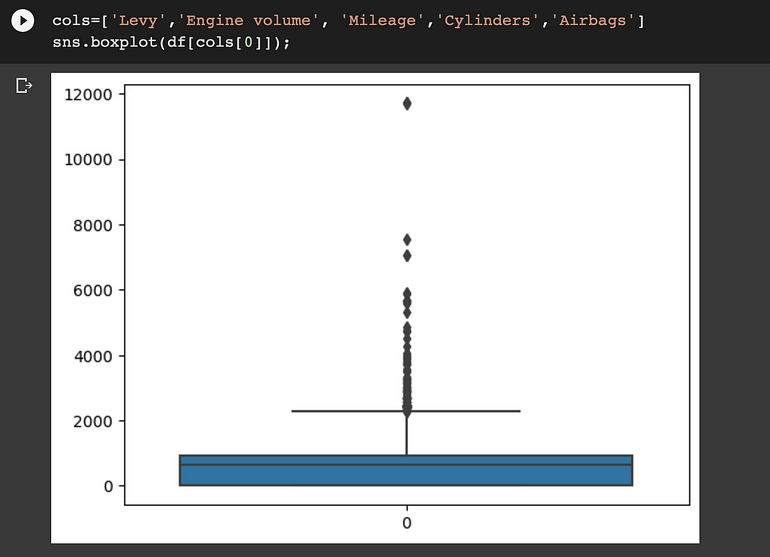
我们将检查数值特征。以下是确定异常值的每个数值特征的快照
Levy:
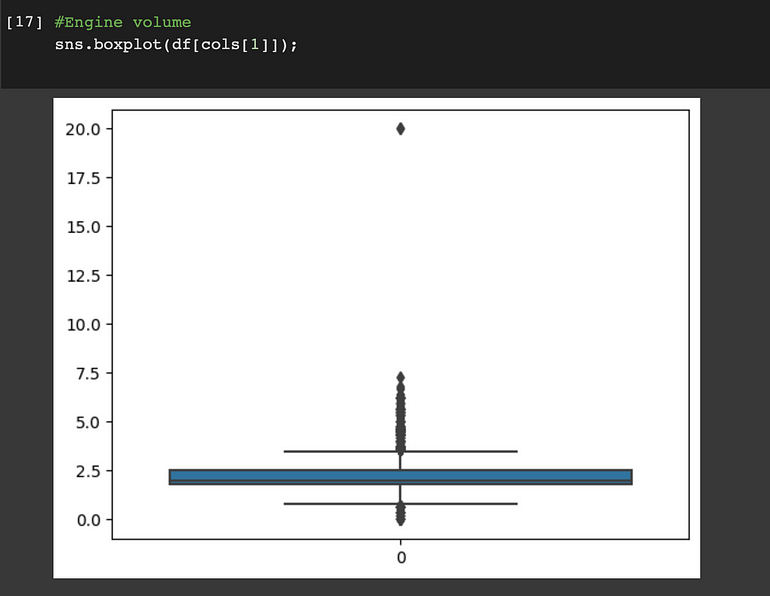
Engine volume:
Mileage:
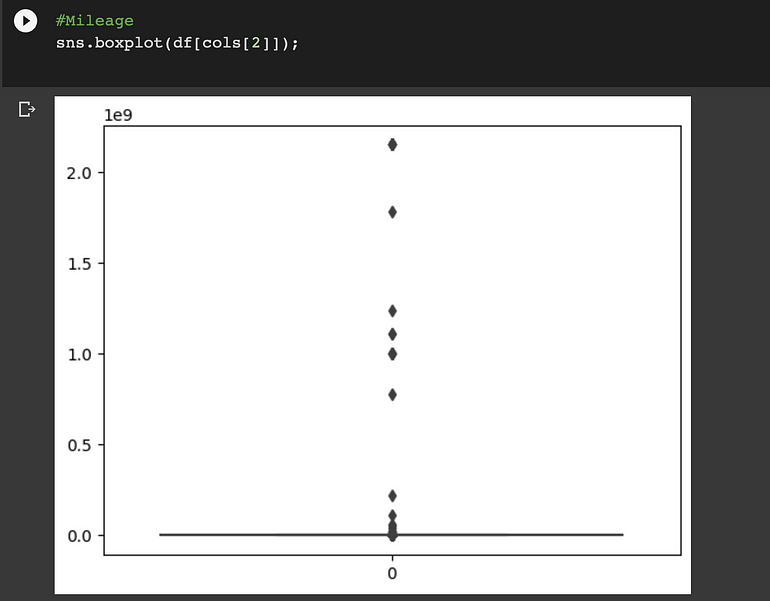
Cylinders:
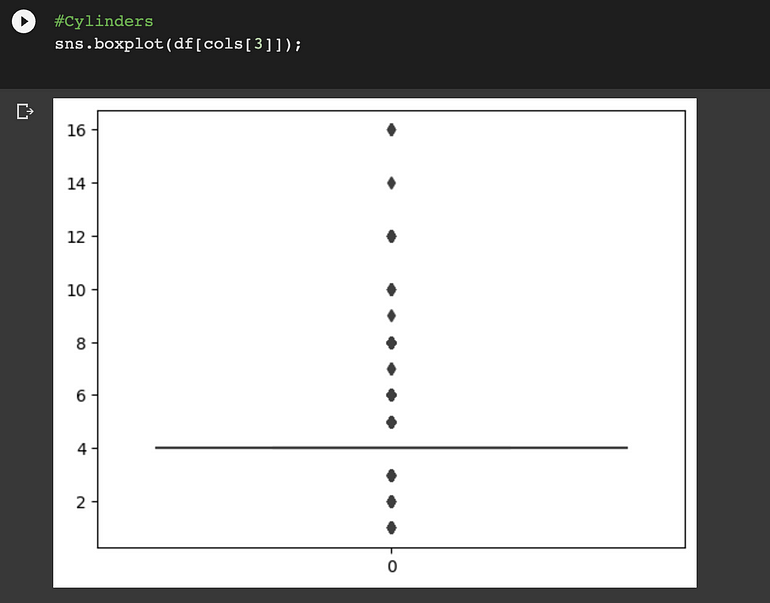
Airbags:
离群值可以在 ‘Levy’, ‘Engine volume’, ‘Mileage’和“Cylinders”列中找到。我们将使用分位数间距 (IQR) 方法来消除这些异常值。
在统计学中,四分位数间距 (IQR) 是基于将数据集划分为四分位数的可变性度量。IQR 是上四分位数和下四分位数之间的差值。它是一种不受异常值影响的稳健的传播度量。IQR 通常用于识别数据集中的异常值。
要计算 IQR,首先需要计算数据集的第 25 个和第 75 个百分位数,然后通过从第 75 个百分位减去第 25 个百分位来计算 IQR。
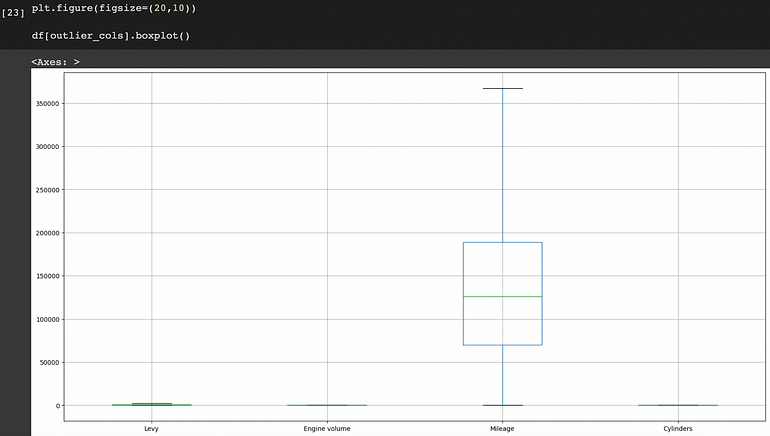
使用 IQR 方法去除异常值后
我们可以观察到现在特征中没有异常值。
开发额外的特征
“Mileage”和“Engine Volume”都是连续变量。在运行回归时,我发现对这些变量进行分箱有助于提高模型的性能。因此,我正在为这些特征/列开发“Bin”特征。

用于开发额外特征的代码截图
处理分类特征
处理机器学习中的分类特征是一项重要任务,因为大多数机器学习算法都是为处理数值数据而设计的。分类特征是表示为字符串的非数值数据,例如颜色、国家或食物类型。为了在机器学习模型中使用这些特征,需要将它们转化为数值数据。
有几种方法可以处理 ML 中的分类特征。我使用 Ordinal Encoder 来处理分类列
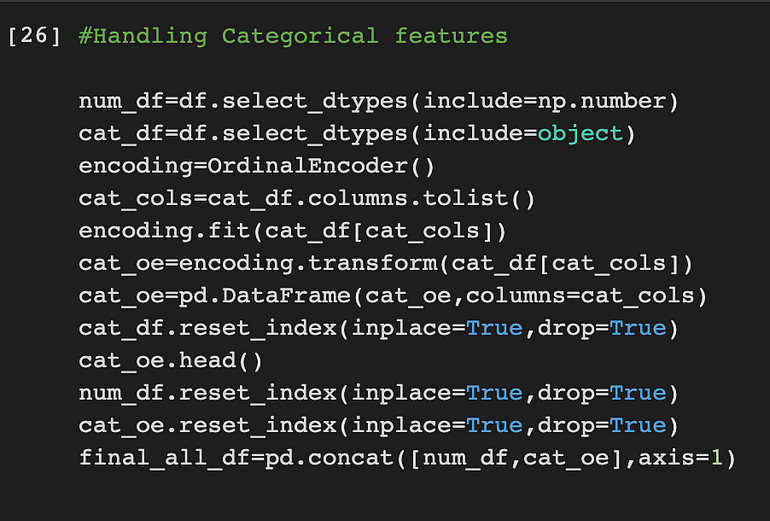
检查相关性
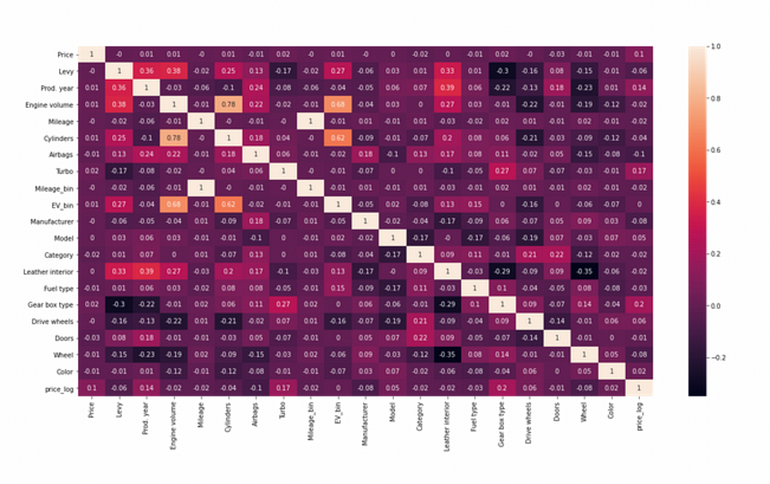
数据显示,特征没有高度关联。然而,我们可以看到,在对“价格”列进行对数转换后,与一些属性的相关性上升了,这是一个积极的事情。我们将利用对数转换的“价格”来训练模型。
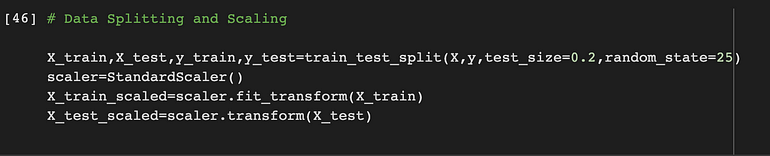
数据拆分和缩放
在数据上,我们将其分为 80-20。80% 的数据将用于训练,其余 20% 将用于测试。
我们将另外缩放数据,因为并非数据中的所有特征值都具有相同的比例,并且具有不同的比例可能会导致模型性能不佳。
模型搭建
作为机器学习模型,我们创建了 LinearRegression、XGBoost 和 RandomForest,以及两种深度学习模型,一种是小网络,另一种是大网络。
我们开发了 LinearRegression、XGBoost 和 RandomForest 基础模型,所以就不多说了,但是我们可以看到模型总结以及它们如何与我们构建的深度学习模型收敛。
深度学习模型——小网络模型总结

深度学习——小型网络模型摘要快照
深度学习模型——小型网络训练和验证损失
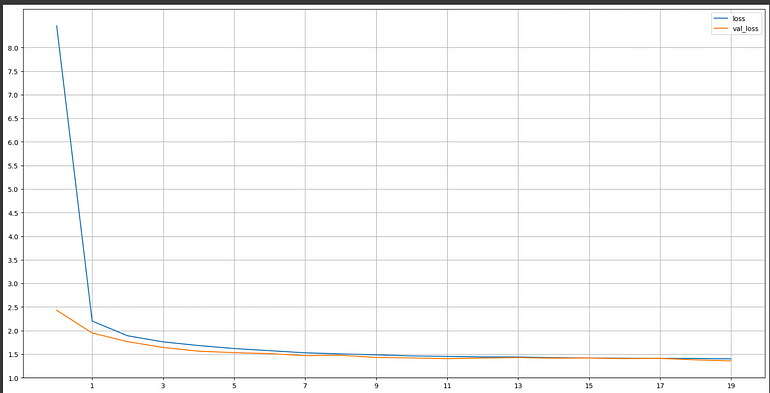
深度学习模型——大型网络
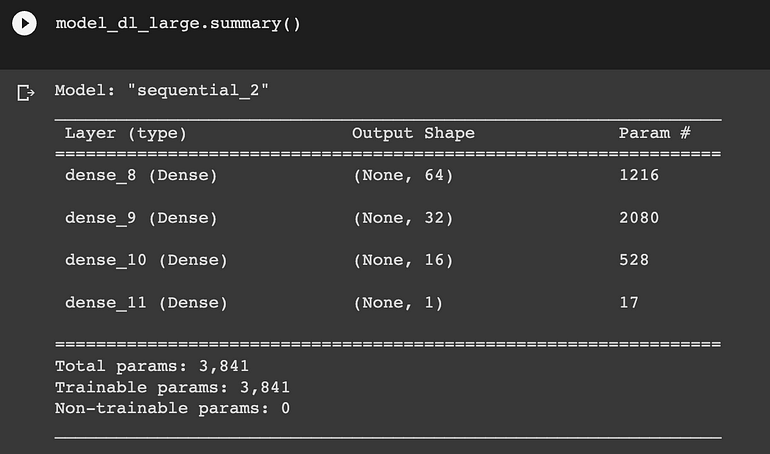
深度学习大网络模型总结
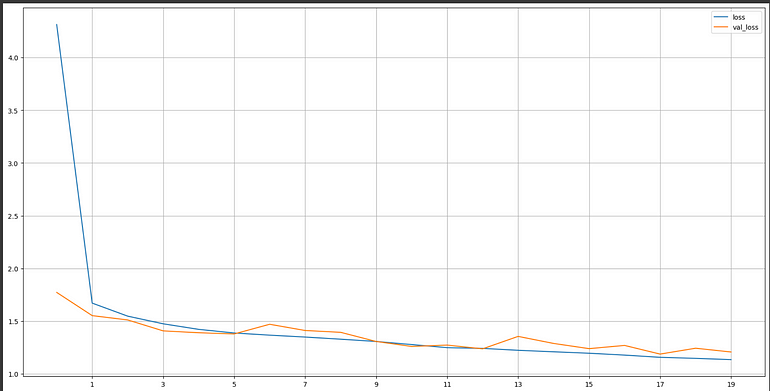
深度学习——大型网络训练和验证损失
模型效率:
我们使用性能矩阵 Mean_Squared_Error、Mean_Absolute_Error、Mean_Absolute_Percentage_Error 和 Mean_Squared_Log_Error 评估模型,结果如下所示。
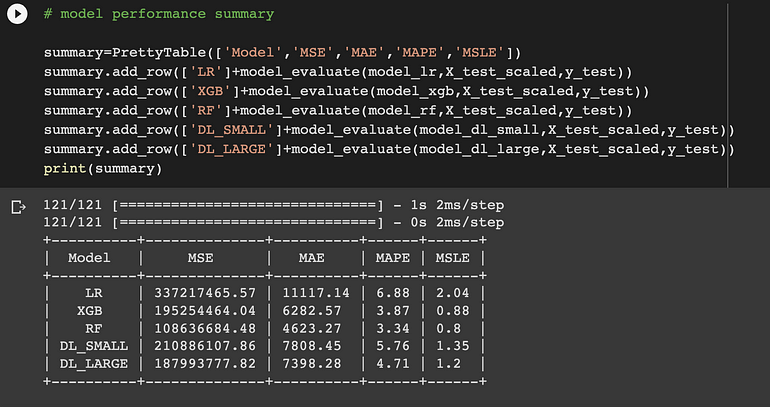
我们应用于数据集的所有模型的摘要
我们可以看到深度学习模型优于机器学习模型。RandomForest 优于所有机器学习模型。
结果
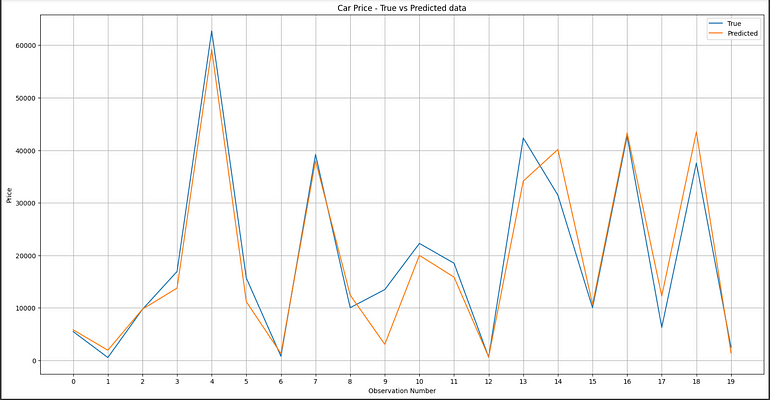
随机森林模型的可视化
从图中可以看出,模型的性能非常好,性能矩阵证明了这一点。
特征重要性
特征重要性是机器学习 (ML) 中的一个重要概念,因为它有助于识别数据集中最相关的特征以预测目标变量。它允许建模者了解每个特征在预测目标变量中的贡献,并有助于识别对模型性能无用甚至有害的特征。
下面我们使用 SHAP 绘制了随机森林模型的特征重要性:
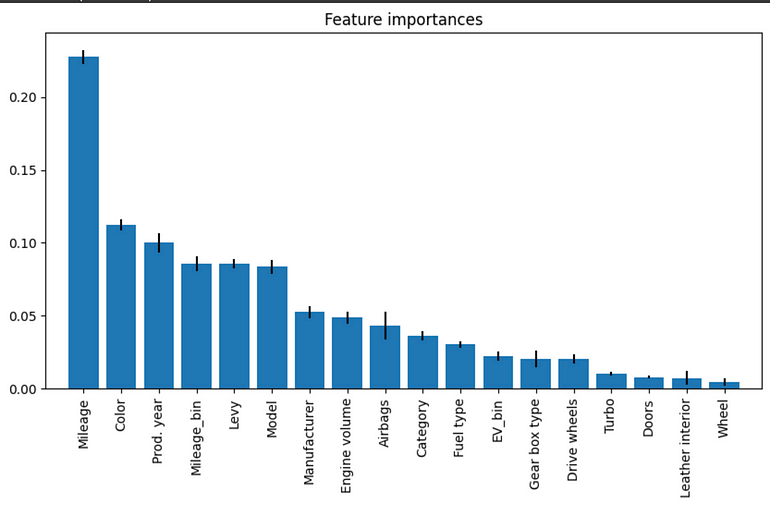
所有变量的特征重要性快照
结论
在本文中,我们尝试使用汽车数据中提供的众多参数来预测汽车价格。我们构建了机器学习和深度学习模型来预测汽车价格,并发现基于机器学习的模型在这些数据上的表现优于基于深度学习的模型。
笔记本参考和代码:
https://colab.research.google.com/drive/1-ivt7AjvEXMXdglMn5AHlTAMfW5oKT3J#scrollTo=J-2Z03_7_8iq
参考文章:
https://www.obviously.ai/post/data-cleaning-in-machine-learning
https://shap.readthedocs.io/en/latest/index.html
原文标题 : 使用机器学习和深度学习模型预测汽车价格
上一篇 : 在 Python 中使用 OpenCV 构建 Color Catcher 游戏
下一篇:PyTorch 2简介:卷积神经网络