





预训练大模型最新统一范式
 发布日期:2023-05-06
发布日期:2023-05-06
 浏览量:8885
浏览量:8885
 240
+1
240
+1
本文重点要讲的这篇论文是:
·Unifying Language Learning Paradigms
·2022年5月
·构建一种独立于模型架构以及下游任务类型的预训练策略,可以统一的灵活地适配不同类型的下游任务
·architecture-agnostic、task-agnostic
·也就是说,作者们提出的是一套统一框架/方法论,可以适用于任何一个task。
这篇文章放出后引出了不小的水花,可以说是LM领域的一个重磅炸弹
·一部分学者对这篇文章的态度是「好哇,终于大统一了,开启了PLM新纪元了吧,以后用起来也更方便了」
·另一部分学者对这篇文章的态度是「天呐,大统一了,这不是断了大家的路了,别人还怎么玩呀」
这篇文章可以概括为是「预训练模型训练范式的统一」
·有、东西,值得一讲
其实在本篇文章出现之前,业界就已经有很多工作在或多或少的研究模型结构/任务统一的问题了
·所以本次分享同时会带大家对这些前人工作进行简单的回顾,因此前半部分可能会有一些像综述,但我们的重点还是会放在这篇文章上。
目录
大模型现存问题
大模型统一趋势
前人工作:Overview
本篇文章:UL2:统一的语言模型范式
参考文献
背景
大模型现存问题
各种各样的模型
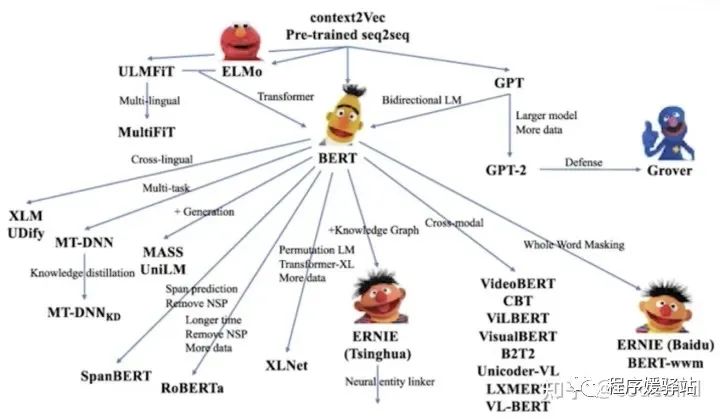
“不完全展示”
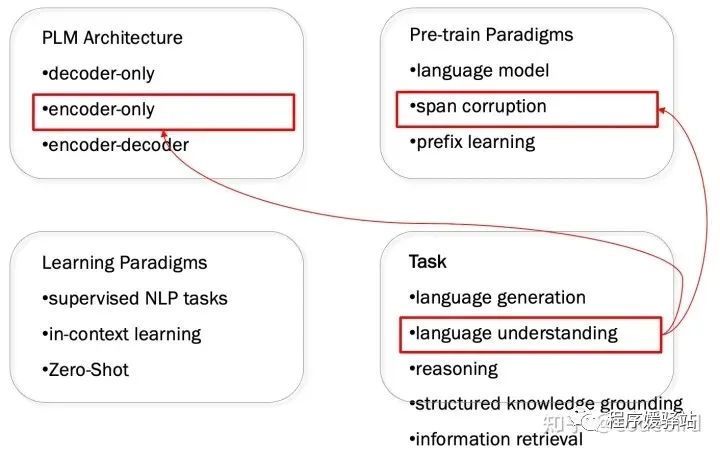
各种各样的范式
PLM Structure
·decoder-only(如GPT)
·encoder-only(如BERT)
·encoder-decoder(如T5)
Pre-train Paradigms
·language model(单向文本建模的 CausalLM,如GPT)
·span corruption(双向文本建模,如Bert、T5)
·prefix learning(前缀文本建模的 PrefixLM,如UniLM)
Learning Paradigms
·supervised NLP tasks
·in-context learning /few-shot
·Zero-Shot
Task
·language generation
·language understanding
otext classification
oquestion answering
·reasoning
ocommonsense reasoning
olong text reasoning
·structured knowledgegrounding(基于结构化知识数据的任务可以统称为 StructuredKnowledgeGrounding (SKG))
·information retrieval
【task-specific LM】
需要根据下游任务类型选用特定的预训练范式/策略
目前大家依旧在延续根据任务选择PLM的习惯,比如:
·生成任务:AR/ encoder-decoder / decoder-only /(language model)
·判别任务:AE/ encoder /(span corruption)
不同的范式建模了不同的上下文关系,也正是因为如此,不同的预训练范式适配不同类型的下游任务。
·也就是说,具体的下游任务类型需要选用特定的预训练策略。
·LM : -> task-specificLM
·也就是说,我们在PLM的使用中,已经潜移默化的把LM变成了task-specific的LM
比如
虽然前文展示的是一种基于经验的面向task的模型选用方法,但是到目前为止,对于不同task如何选择正确的architecture和pre-training策略(自监督目标),似乎仍然没有达成共识。
这就引发了一种思考:
··为什么“ pre-trained LM的选择要取决于下游的任务?”
··我们能不能,以及 “如何能在许多任务中普遍有效的预训练模型?”
缺点&问题
问题:
·PLM的选择,在一定程度上牵制了研究者的精力和资源;
·而且,在应用场景上也会受硬件环境限制,为不同的下游任务部署特定的模型,是一个很消耗资源的方式。
因此,「一个统一的大模型」是必然的。
·研究:集中精力改进和扩展单个模型,而不是在 N 个模型上分散资源。
·应用:在资源受限的环境下,有一个可以在多种任务上表现良好的预训练模型。
大模型统一趋势
在这种背景下,「模型大一统」是趋势
·其最终目的都是为了面对不同的任务时,能够使用统一的PLM,不再被PLM架构/训练策略的选择牵制精力/资源
·task-specific LM ->Task-Agnostic LM
o(Agnostic:无感知的,不被牵制的)
·所谓Task-Agnostic 包括
oTask-Agnostic 的 PLM Structure
§•decoder-only
§•encoder-decoder
oTask-Agnostic 的 Pre-train Paradigms
§·language model
§·span corruption
§·prefix learning
优点&好处
通用模型的优势是显而易见的
·有了通用模型,研究者就可以集中精力改进和扩展单个模型,而不是在 N 个模型上分散资源。
·此外,在只能为少数模型提供资源的受限环境下,最好有一个可以在多种任务上表现良好的预训练模型。
前人工作
我们也在近些年的论文中看到了一种未来趋势:模型大一统「Unified」,目前的论文中的统一可以概括为以下两种角度:
·结构统一:通过一些对PLM结构或策略的改动,统一不同PLM结构的优点,规避缺点问题,如XLNet
·任务统一:改变PLM结构或任务表示(multi-task learning),使一种模型具备处理多种不同任务的能力,如T5
·模态统一:同时进行单模态和多模态的内容理解和生成任务,如Unimo(已有的预训练模型主要是单独地针对单模态或者多模态任务,但是无法很好地同时适应两类任务。同时,对于多模态任务,目前的预训练模型只能在非常有限的多模态数据(图像-文本对)上进行训练。)
我们首先回顾一下近几年来的几个相关论文,这些论文大家都比较熟悉了,这里就带大家从另一个角度简单回顾一下。
·简单回顾这几个模型的原因,
o一是:因为他们确实在模型统一上做了一些工作并且效果也是很好的,
o二是:虽然这几篇工作在完成一些模型统一的事情,但却都并没有站在一个相对比较高的角度对现有“大模型们”进行完全的统一。
模型
作者
思想
模型架构
预训练策略
任务类型
XLNet
MS2019
融合AR/AE两类模型的优点,解决BERT中pretrain和finetune阶段mask存在不一致的问题
基于bert的encoder-only
提出 Permuted Language Modeling
主要做理解任务
MPNet
MS2022
继承了MLM和PLM的优点,避免了它们的局限性
基于bert的encoder-only
采用Permutaion language modeling
主要做理解任务
MASS
MS2019
整合了transformer的Encoder和Decoder部分,相当于BERT和GPT的结合体
encoder-decoder
与bert-mask一样,加大mask为句子长度的0.5,decoder时进行预测
主要做生成任务
BART
Facebook2019
提出了一个结合双向LM和自回归LM的预训练模型
encoder-decoder
不同于MASS的是,BART对decoder没有进行改变。
理解任务/生成任务
UniLM
MS2019
调整不同的attention mask,实现NLU与NLG的统一预训练模型
基于bert的encoder-only
提出Prefix LM使用3种语言模型优化目标
理解任务/生成任务
T5
MS2019
把所有任务都转化成Text-to-Text任务
encoder-decoder
通过大量实验最终选出corruption rate
理解任务/生成任务
XLNet、MPNet
XLNet、MPNet采用Permutaion languagemodeling,兼顾上下文与自回归,融合两者优点,避免局限性。
XLNet
·2019.06
·arxiv.org/abs/1906.0823...
做法
·针对AE与AR的优缺点:
oAE能够看到上下文但忽略了[Mask]之间的相关性
oAR天然的适合生成任务但只能看到单向信息
·提出了PLM
oPermutaion languagemodeling:一个序列随机换位方法,并以自回归的方式预测右边部分(predictedpart)的token
o融合了AR模型(类GPT,ELMo)和AE模型各自的优点,既能建模概率密度,适用于文本生成类任务,又能充分使用双向上下文信息。
·XLNet实现AR和AE融合的主要思路为,对输入文本进行排列组合,然后对于每个排列组合使用AR的方式训练,不同排列组合使每个token都能和其他token进行信息交互,同时每次训练又都是AR的。
优点:
·融合了BERT和GPT这两类预训练语言模型的优点,
·并且解决了BERT中pretrain和finetune阶段存在不一致的问题(pretrain阶段添加mask标记,finetune过程并没有mask标记)
MPNet
·2020.04
·arxiv.org/abs/2004.0929...
·针对MLM和PLM的优缺点:
oMLM可以看到全句的位置信息,但不能对预测token之间的依赖关系进行建模,不能很好地学习复杂的语义关系;
oPLM可以通过自回归预测对predicted tokens之间的依赖关系进行建模,但不能看到全句的位置信息,由于在下游任务中可以看到全句的位置信息,会造成预训练和微调的不匹配。
·为了继承了MLM和PLM的优点,避免它们的局限性
基于bert的encoder-only结构,对预训练的目标进行改动
这两个任务虽然在努力的融合不同LM,但是他们的重点依然在LM结构的优化上(融合现有结构的优点&规避缺点),并非在统一不同任务对应的PLM上。
MASS、BART
·MASS:ICML 2019
·BART:ACL2020
BART
·提出了一种新的预训练范式,包括两个阶段:首先原文本使用某种noise function进行破坏,然后使用sequence-to-sequence模型还原原始的输入文本。
·下图中左侧为Bert的训练方式,中间为GPT的训练方式,右侧为BART的训练方式。
·首先,将原始输入文本使用某些noise function,得到被破坏的文本。这个文本会输入到类似Bert的Encoder中。在得到被破坏文本的编码后,使用一个类似GPT的结构,采用自回归的方式还原出被破坏之前的文本。
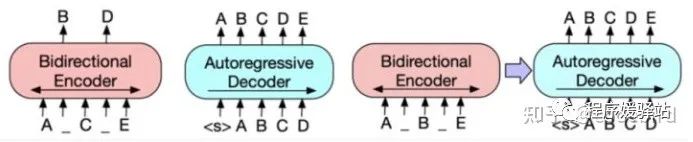
MASS专注于生成任务,BART在保证理解任务性能的前提下,生成任务的结果也得到提升。
·总体来看,这两个模型有相似也有不同,MASK的方式对预训练模型的结果影响很大。
·BART和MASS对生成任务的效果都有提升。
基于Transformer的encoder-decoder结构,对encoder的mask方式进行改动
主要贡献:BART提出了一个结合双向LM和自回归LM的预训练模型。
但其仅仅将「双向如BERT」与「自回归如GPT」结合在一起,而PLM的范式除此之外还有单向LM (left2right/right2left/left2right+right2left如ELMO等)。
并不能称作「统一」。
UniLM(•结构统一)
UniLM是一种BERT-based的生成模型
·NeurIPS2019
·arxiv.org/abs/1905.0319...
本文提出了采用BERT的模型,使用三种特殊的Mask的预训练目标,从而使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果。模型使用了三种语言模型的任务:
·unidirectional prediction
·bidirectional prediction
·seuqnece-to-sequenceprediction
认为EMLo采用前向+后向LSTM、GPT采从左至右的单向Transformer、BERT采用双向Attention都有优缺点。
·融合了3种语言模型优化目标,通过控制mask在一个模型中同时实现了3种语言模型优化任务,在pretrain过程交替使用3种优化目标。
·三种:unidirectional(left2right/right2left)/seq2seq/bidiectional
·采用的Multi-tasktraining,
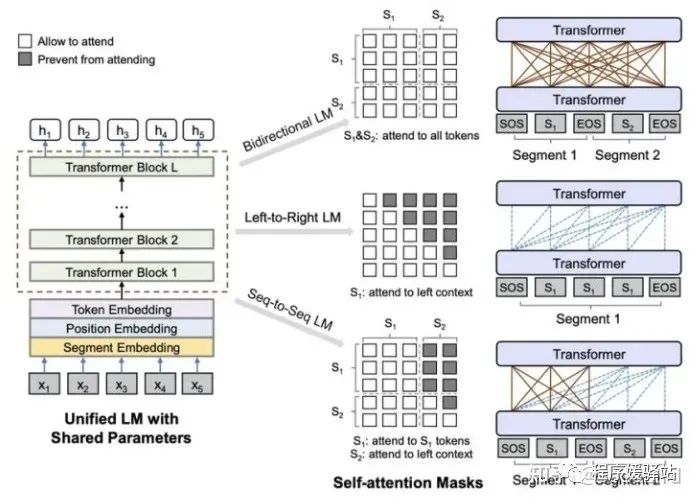
基于bert的encoder-only结构,使用三种特殊的Mask的预训练目标控制attention,使得3种类型可以存在于同一个LM 中,并可以同时训练。从而使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果。
核心思路是利用mask控制生成每个token时考虑哪些上下文的信息。
相对上面的几篇文章来说,个人认为UniLM可以算是LM的「小」统一 ?(把不同的优化目标统一在同一个LM中)。
T5(•任务统一)
arxiv.org/abs/1910.1068...
本文的重要贡献
·以一种统一的思想研究PLM,并用了大量实验来验证效果。把所有的NLP问题都可以定义成“text-to-text”问题,即“输入text,输出text,一个模型干所有”。(还得是有钱)
·顺便贡献了个语料库C4(Colossal Clean Crawled Corpus)
下游任务
·machine translation:WMT English to German, French, and Romanian translation
·question answering:SQuAD
·abstractive summarization:CNN/Daily Mail
·text classification:GLUE and SuperGLUE
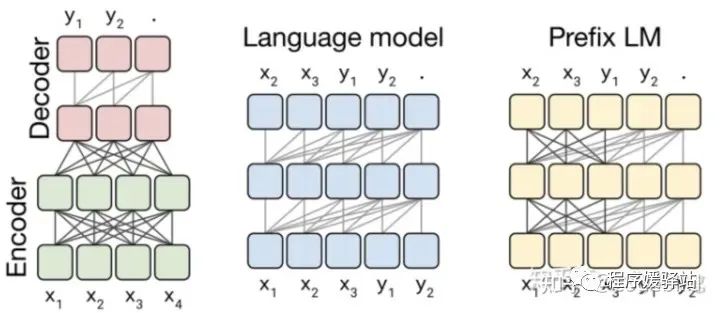
三种Model structures:Encoder-decoder、Language model、Prefix LM
·代表分别有 MASS(BERT 可以看作是其中 Encoder 部分)/ GPT2 / UniLM
·在同一种模型结构下,这三种架构依旧是通过注意力机制的 Mask 控制
·其实就是介绍了三种attention mask:
·Fully-visible(transformer的encoder那种mask),BERT-style
·Causal(transformer的decoder那种mask),LM,GPT-style
·Causal with prefix(前两种的结合,前半段是fully-visible,后半段是causal)。
·在同样运算复杂度的情况下,Encoder-decoder结构的参数量是其他结构的两倍左右。
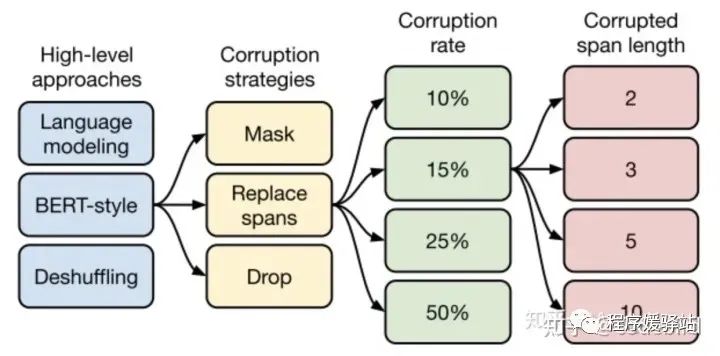
三种Unsupervised objectives:
·LM(GPT从左到右)/BERT-style(denoising还原)/Deshuffing(XLNet文本打乱还原) -> BERT(Table4)
·BERT-style 的三种 variant 中 span wins!(Table 5)
·corruption rate 15% wins!(Table 6)
·Results:Encoder-decoder配合denoisingobjective达到了最好的效果。详见原文Table 2。
T5这篇论文如果只从技术上来讲,他其实是没有太多的idea创新的,但他的一个重要作用在:将NLP 任务都转换成 Text-to-Text 形式,然后使用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
可以简单概括为:
·基于标准encoder-decoderTransformer结构(在不同的具体任务上有不同的prefix指导模型),对预训练目标进行大范围探索,(类似这样的大型实验探索论文也有一些:首先提出一个通用框架,接着进行了各种比对实验)最后获得一套建议参数,最后得到一个很强的 baseline。而我们之后做这方面实验就能参考它的一套参数。
T5通过提出一套通用方法并进行大量实验,确实提出了一套统一的大模型结构(大量实验下的到的一套经验参数以及一个 baseline:denoising+replacespan+corruption rate 15%)。
但是,这一套参数一定就比其他的参数要好呢?在任何情况下都适用吗?
我们追求的「模型大一统」应该不仅仅是使用「同样的模型,同样的损失函数,同样的训练过程,同样的解码过程」就可以,而是统一的模型/损失函数/训练目标/解码过程是真的具备解决各类任务(生成/理解/推理等)的能力或者可以灵活适配。
重点比较:T5 & UniLM & UL2
前面都比较好理解
但在讲UL2这篇文章之前,大家会觉得T5(那么多的实验,那么多的),UniLM也貌似统一了NLU和NLG。
他们或许都已经足够“统一”了,那为什么还需要UL2呢?
其实他们还是有很大不同的,所以这里先提前提及一下他们的区别:
·T5:将 NLP 任务都转换成 Text-to-Text 形式,然后使用同样的模型(encoder-decoder),同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
·UniLM:通过控制mask在一个模型中同时实现3种语言模型优化任务,使encoder-only模型可以同时完成NLG任务。
·UL2:构建一种 独立于模型架构 以及 下游任务类型 的预训练策略(自监督目标),可以灵活地适配不同类型的下游任务。
·【从这里看起来,UL2工作的落点是要比现有的这些工作更高的,并且分离了arch和pretrain-obj】
模型结构
预训练策略(自监督目标)
T5
encoder-decoder
在各种现有策略中实验,最终选定表现最好的策略为span corruption
UniLM
Encoder-only
BERT模型+三种特殊的Mask的预训练目标,使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果。
UL2
普遍适配
提出Mixture-of-Denoisers (MoD)融合了Prefix LM/span corruption/CLM不同的模型能力
然后我们再来展开讲一下这篇论文
UL2(该论文所提出的方法叫法)

2022年5月,Google提出一种“无关architecture”“无关task”的预训练策略,即,此策略无论什么PLM architecture 什么task 都可以灵活适配。
·architecture-agnostic
·task-agnostic
论文:Unifying Language Learning Paradigms
·arxiv.org/pdf/2205.0513
·zhuanlan.zhihu.com/p/51
·也就是说,作者们提出的是一套框架(方法论),可以适用于任何一个task,并且可以适配任何architecture。
趋势及问题
通过前面的介绍,我们可以看出,其实从UniLM、T5甚至更早,大模型统一的趋势已经非常清晰明了,
但由于上述问题,我们还是没办法心甘情愿的称之为「模型大一统」(不再依赖任务选择PLM)。
论文讲解
跳转:
*重点在此*
本文内容有点多了,关于这篇论文的细节,打算再开一篇文章细写
占坑占坑占坑占坑占坑占坑占坑占坑占坑占坑占坑占坑占坑占坑
总结
本文贡献「迈向建立普遍适用的语言模型的一步」
•将architectural archetypes与pre-training目标分开
•预训练策略比预训练架构更重要(这两个概念通常是合并在一起的)
•提出了一个pre-training目标:Mixture-of-Denoisers(MoD)
•提出了一个广义统一的NLP自监督视角,通过不同的pre-training目标相互转换,将不同的pre-trainingparadigms结合在一起
•引入了模式切换的概念
•其中下游fine-tuning与特定的pre-training schemes相关。
•最后,通过将模型扩展到20B参数,在50个已建立的监督NLP任务上实现了SOTA性能
•这些任务包括语言生成(带有自动化和人工评估)、语言理解、文本分类、问题回答、常识推理、长文本推理、结构化知识基础和信息检索。
总结&思考&工作启发
本文UL2的重点在:
·「提出一种“无关architecture”“无关task”的预训练策略,即使用此策略训好的PLM无论什么architecture什么task都可以灵活适配」
·即:不需要再根据任务去选择 architecture 及预训练策略(自监督目标)
·architecture-agnostic& task-agnostic
在解决 task-specific LM 的问题上,还有一种常用做法:Massive Multi-tasking
·后Prompt的产物,Fintune范式+Prompt范式的综合体
·重点在:对下游任务形成拿来即用的模型,可直接进行zero-shot测试,也可进一步提升few-shot性能。
·是统一场景下的解决方案之一
·更多推荐阅读:zhuanlan.zhihu.com/p/46...
参考文献
论文
·Unified Language ModelPre-training for Natural Language Understanding and Generation
·GeneralizedAutoregressive Pretraining for Language Understanding
·DenoisingSequence-to-Sequence Pre-training for Natural Language Generation, Translation,and Comprehension
·Unifying LanguageLearning Paradigms
博客
·https://zhuanlan.zhihu.com/p/513800476
·https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650845731&idx=1&sn=24617480239384699ed9ab91da561739&chksm=84e5765db392ff4b2608d4c9726c9403ababd30dff2e5225e8731c05efe1523f8d4631317236&mpshare=1&scene=1&srcid=0515lVkpTYBe5aJHZkEZF3t7&sharer_sharetime=1652546097545&sharer_shareid=12c0d348dc52e0610c03a370c1241fe3&version=4.0.0.6007&platform=win#rd
·https://zhuanlan.zhihu.com/p/501841063
·https://zhuanlan.zhihu.com/p/482465145
·https://zhuanlan.zhihu.com/p/386470305
·https://zhuanlan.zhihu.com/p/465130047
·https://zhuanlan.zhihu.com/p/89719631
·https://zhuanlan.zhihu.com/p/88377084
·http://www.360doc.com/content/22/0110/07/7673502_1012609753.shtml
原文标题 : 预训练大模型最新统一范式
上一篇 : 车位数量检测
下一篇:使用 CNN 进行面部情绪识别